
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- java
- 네이버웹툰크롤링
- classic retention
- 웹크롤링 실습
- range retention
- 파이썬 야구게임
- 구구단
- R실습
- rolling retention
- r연습문제
- 특정값 추출
- 피처벡터화
- requests 모듈
- 함컴타자연습
- 문자열reverse
- 파이썬
- 문자열함수
- R
- 조건인덱싱
- 데이터프레임조회
- 웹크롤링
- 데이터프레임 정보 조회
- 파이썬예제
- 웹크롤링 예제
- Python
- 야구게임 코드
- pandas
- 프로그래머스 풀이
- R기초
- 타자연습파이썬
Archives
- Today
- Total
서비스 기획자의 성장기록
[웹 크롤링/데이터수집] 언론사별 랭킹 뉴스 추출하기 본문
네이버 뉴스 (news.naver.com) 랭킹에서 언론사 별 Top 5 랭킹 뉴스의 헤드라인을 가져오겠습니다.
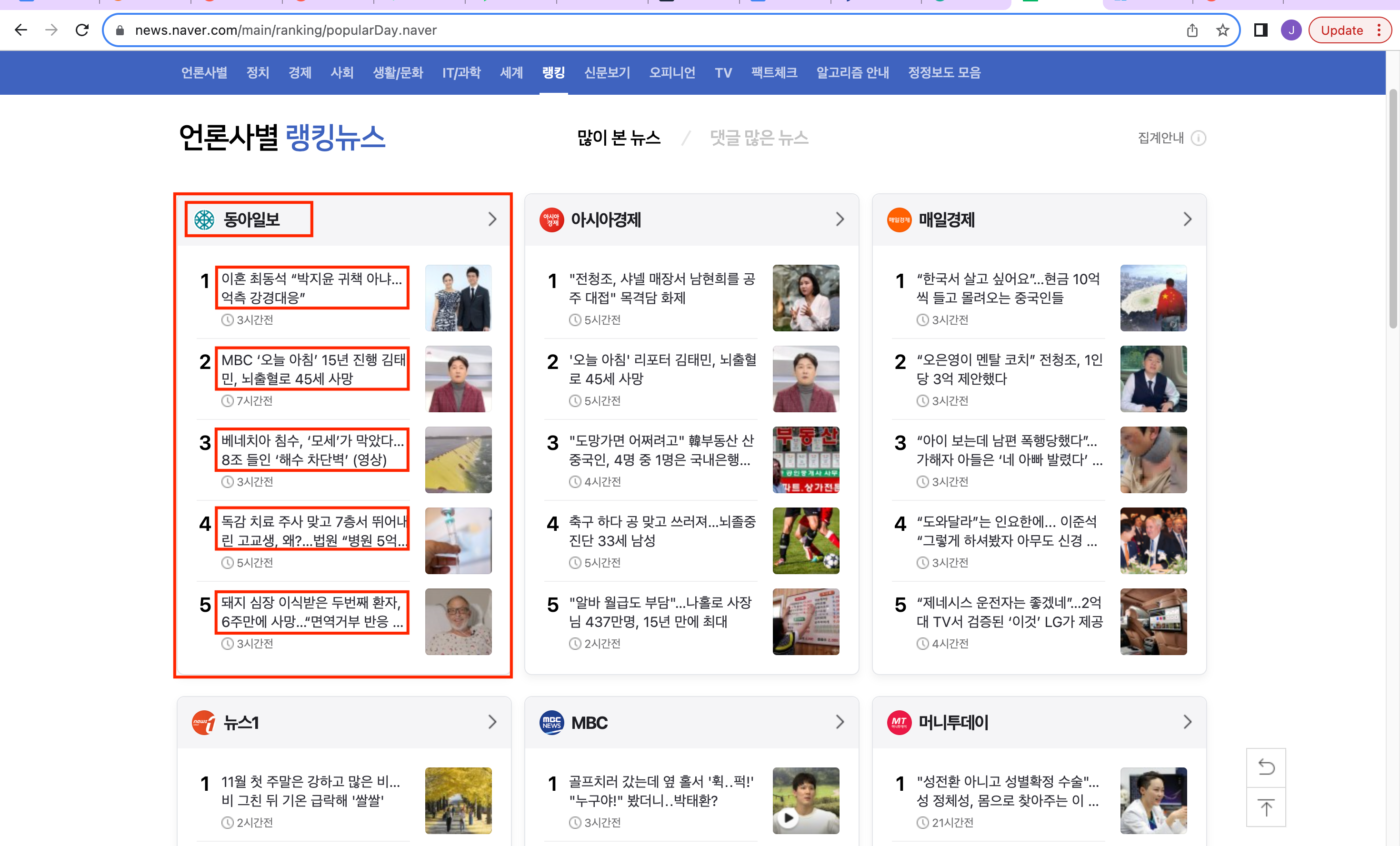
스크립트:
import requests
from bs4 import BeautifulSoup
url = 'https://news.naver.com/main/ranking/popularDay.naver'
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
ranking_news = soup.find_all('div', attrs={'class':'rankingnews_box'})
for news in ranking_news:
press_name = news.find('strong', attrs={'class':'rankingnews_name'})
headlines = news.find_all('a', attrs={'class':"list_title nclicks('RBP.rnknws')"})
print(press_name.text)
for headline in headlines:
print(headline.text)
print()
1. 언론사 객체 별 영역 - html 태그 확인
먼저, 개발자 모드에서 각 언론사 별 데이터를 포함한 영역을 확인하면
<div> 태그의 class='rankingnews_box'속성을 가진 곳에 있는것을 확인할 수 있습니다.

2. 헤드라인 영역 - html 태그 확인
헤드라인은 class = "list_title nclicks('RBP.rnknws')" 속성을 가진 <a> 태그에 있습니다.

3. User-agent 값 전달하기
requests.get()함수로 url에 직접 접근하면 웹페이지에서 봇으로 인식해서 'connection error🚨'가 뜹니다.
그래서 headers 값으로 user-agent를 전달해서 불러옵니다.

4. 언론사별 랭킹뉴스 헤드라인 출력하기
news는 각 언론사별 rankingnews_box 객체입니다.

따라서 언론사 이름은 하나가 포함되어있기 때문에 find() 함수를 사용해서 불러와줍니다.
그리고 각 headline은 for 문을 사용해서 하나씩 출력합니다.
결과:


끗!
'웹 크롤링 > 데이터 수집 (Python)' 카테고리의 다른 글
| [웹크롤링] 유용한 스크립트 모음 (0) | 2023.11.02 |
|---|---|
| [웹크롤링/데이터 수집] 네이버 웹툰에서 요일별 웹툰 목록 가져오기 (0) | 2023.11.02 |
| [웹 크롤링/데이터 수집] Request 모듈로 원하는 데이터 불러오기 (1) | 2023.10.31 |
'웹 크롤링/데이터 수집 (Python)' Related Articles
more

